A harrowing tale of trying to solve the impossible and failing. Episode 5 in this year’s run at the #100DaysToOffload challenge. See the full series here

Photo by Tim Mossholder from Pexels
That’s So Random: Randomness in Machine Learning
Training Machine Learning and in particular Deep Learning models generally involves a lot of random number generation. If we’re training a supervised classifier or regressor, we tend to randomly split our annotated data training set from our test set. Also, if you are training a new neural network it is fairly standard practice to randomly initialize the connections between the neurons (the weights) with a random number (here’s why).
However, all this randomness goes against one of the basic tenets of scientific research: reproducibility. I.e. in order to be sure that the results of an experiment weren’t just down to luck or chance (or that the person who carried out the work didn’t make up their results), it is really important that the results can be reproduced.
Loading the Dice: Pseudo-Randomness and Seeds
So how do we reconcile these things? Well, by happy coincidence, random operations on computers are not really random at all, they are pseudo-random. That means that although the numbers generated may appear random, they are actually predictable based on an initial starting point called the seed number. Most of the time the seed is set to the current time so you’ll get pretty much perfectly random numbers every time.
Within the machine learning community, it’s best practice to fix the random seed to a known value for all experiments. That way the random operations are still statistically random for the purposes of the model but they are always exactly the same for every subsequent run of the program which means that, in theory, the program should be perfectly reproducible as long as the random seed is set.
A Walkthrough of My Fool’s Errand
Earlier this week I panicked because an experiment I’ve been working on was giving fairly different results depending on whether I trained it on my desktop or a cloud VM. We’re talking performance levels of each other within 10% F1 score but the thing is, I’d set all my random seeds to 42 so, in theory, the results should be exactly the same. What was going on?
I meticulously sank lots of time into checking that the files I was using for testing and training were exactly the same. I use dvc for tracking all of my experiments including parameters, input files and output files so it’s possible (I wouldn’t go as far as trivial) for me to check that all of these things add up by looking at the file hashes in the DVC lock file.
Everything looked the same so then I started stepping through the code line-by-line in interactive debuggers running on both my desktop and the server.
I was able to verify that the exact same batches of text were being passed in with exactly the same mapping onto embeddings:
Desktop inputs in memory:  Server inputs in memory:
Server inputs in memory: 
I ran the inputs through a single pass of the RoBERTa-based model and that was when things got a bit weird:
Desktop RoBERTa output: 
Server RoBERTa output: 
The outputs are in the same ballpark but they are quite different even within 2 significant figures. This should be impossible since I set the random seed to identical values on both machines, the input files are the same and the software libraries are the same. What is going on?
Well… it turns out that this is a known problem according to some of the community experts over at the pytorch forum. The problem comes down to the way that the way that floating point operations are handled by different GPU architectures. Floating points are approximate representations of irrational numbers - they can be very precise but they’re approximations all the same. Once you get to a certain level of precision it becomes a wild west. As alband says over at the pytorch forum:
This is a hardware/floating point limitation. The floating point standard specifies only how close from the real value the result should be. But the hardware can return any value that is that close. So different hardware can give different result
The issue is that neural networks multiply the input signal by a given set of weights to some degree of precision. The differences are then multiplied by each consecutive layer in the network and finally the error signal. This process is repeated thousands or millions of times during training of the network.
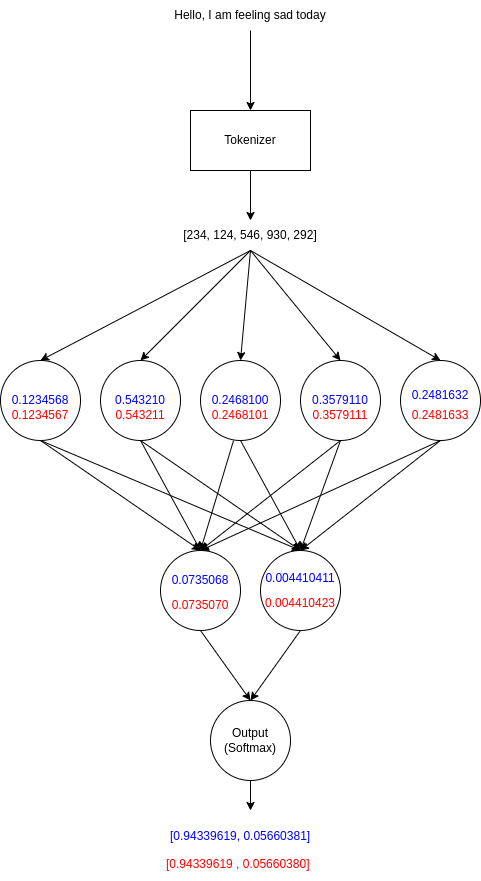
Visualisation of how a small change in calculations made by 2 different computers (red and blue) in the network can propagate in the output and error signal.
gradient descent is very sensitive to these fluctations in the gradient. If you increase the output slightly in one direction you might end up in a local error maxima and in the other, a minima. These small fluctuations can potentially multiply out into relatively large changes to the model for large batches of data hence the differences I was seeing.
Visual representation of gradient descent from wikipedia**
.png){kind=link}
So what can be done?
Well the guys over at pytorch don’t think much can be done although they suggested that it’s worth double checking that my results are reproducible on the same machine. I ran the model again a couple of times on my desktop and got exactly the same outputs so I’m confident that this is the case.
Conclusions are as follows:
- Deep Learning models are only truly reproducible on the same machine and hardware
- It seems reasonable to believe that 2 machines with the same CPU and GPU should behave exactly the same although I’ve not tested this since I don’t have 2 identical machines that I can try running my experiments on.
- Even on the same machine results may not be reproducible if you run your model on your GPU and then on your CPU. Furthermore, some operations on GPUs are non-deterministic (they change even if you set your random seed) so it is worth reading the pytorch documentation about how to ensure your best chances at reproducing your work.
Therefore:
- If you are making changes to the same model - e.g. changing hyperparameters, input data or even network architecture, it is important to use the same machine (or possibly identical machines with the same software + hardware stack) to run your experiments. If you train on separate machines you may not be getting a like-for-like benchmark of your models.
- If you plan to deploy the model into a production inference environment, It is probably worth training your model on the same hardware as you plan to run it on. If that’s not possible then you should run the model over your evaluation set in the final prod environment and see a) if the results are very different and b) if you are happy/accepting of those differences.
Replies & Web Activities
If you would like to comment or reply then toot me or bluesky me about this url, or send me a webmention
3 Likes
3 Comments
@jamesravey chaotic systems! when i was doing speech rec training we would regularly get mandates from the boss or the customer to "improve the frontier graph" by x points or whatever and they'd grill us on what we thought would give that improvement. about I dunno like 50% of the time the result of executing that plan was a degradation of model performance. (this is why I left that gig too, the catch-22 of improving already-optimized chaotic systems was too much)
@capn_b ah that old chestnut! I guess it's almost impossible to avoid overfitting when you're already performing well on general use cases
@jamesravey and that "well" is extremely fun to define!