As of today, I am deprecating/archiving turbopilot, my experimental LLM runtime for code assistant type models. In this post I'm going to dive a little bit into why I built it, why I'm stopping work on it and what you can do now.
If you just want a TL;DR of alternatives then just read this bit.
Why did I build Turbopilot?
In April I got COVID over the easter break and I had to stay home for a bit. After the first couple of days I started to get restless. I needed a project to dive into while I was cooped up at home. It just so happened that people were starting to get excited about running large language models on their home computers after ggerganov published [llama.cpp]. Lots of people were experimenting with asking llama to generate funny stories but I wanted to do something more practical and useful to me.
I started to play around with a project called fauxpilot. This touted itself as an open source alternative to Github Copilot that could run the Salesforce Codegen models locally on your machine. However, I found it a bit tricky to get running, and it didn't do any kind of quantization or optimization which meant that you could only run models on your GPU if you have enough VRAM and also if you have a recent enough GPU. At the time I had an Nvidia Titan X from 2015 and it didn't support new enough versions of CUDA to allow me to run the models I wanted to run. I also found the brilliant vscode-fauxpilot which is an experimental vscode plugin for getting autocomplete suggestions from fauxpilot into the IDE.
This gave me an itch to scratch and a relatively narrow scope within which to build a proof-of-concept. Could I quantize a code generation model and run it using ggerganov's runtime? Could I open up local code-completion to people who don't have the latest and greatest nvidia chips? I set out to find out...
What were the main challenges during the PoC?
I was able to whip up a proof of concept over the course of a couple of days, and I was pretty pleased with that. The most difficult thing for me was finding my way around the GGML library and how I could use it to build a computation graph for a transformer model built in PyTorch. This is absolutely not a criticism of ggerganov's work but more a statement about how coddled we are these days as developers who use these high-level Python libraries to abstract away all the work that's going on whenever we build out these complex models. Eventually, I found a way to cheat by using a script written by moyix to convert the Codegen models to run in a model architecture already supported by the ggml example code. This meant that I didn't need to spend several days figuring out how to code up the compute graph and helped me get my POC together quickly.
Once I'd figured out the model, it was just a case of quantizing it and running the example code, then I made use of CrowCPP to provide a lightweight HTTP server over the top. I reverse engineered the fauxpilot code to figure out what the REST interface needed to look like and started crafting.
When I typed in my IDE and got those first code suggestions back, I got that magical tingly feeling from making something work.
How successful was the PoC?
Once I had my PoC I added a readme, some badges and some CI pipelines for docker images, Mac pkgs and so on. Then I shared my project on Twitter, Reddit and Mastodon. I was surprised at how much attention it got, I accumulated about 2.5k stars on github in the first couple of days, then it slowed down to about 100 stars a day for the rest of the week. I think it helped a lot that Clem from Huggingface retweeted and replied to my tweet:
In the weeks that followed I got emails and linkedin notifications from all over the place. I got invited for coffee by a bunch of investors and I got asked to demo my tool at a large industry event (unfortunately the demo didn't go ahead due to last minute agenda changes. I will leave this totally, completely unrelated link here). I would say that as a proof-of-concept my work was very successful and demonstrated pretty clearly that it's feasible to have a local code assistant that stacks up pretty well against big, centralised models LLMs.
How did the project go after the PoC stage?
After the initial buzz, my progress slowed down quite a bit. Partly because we'd just raised some investment at my day job and things had really taken off and that meant I had less time to spend on the project. Part of it is because this is an area that is moving so fast right now and over the summer there seemed to be new code assistant model releases every week that someone would raise a ticket against. I felt guilty for not being able to keep up with the pace and that made me start to resent the project.
I did have a few exciting highlights though. Once I refactored the code and integrated Nvidia GPU offloading, I was getting blazingly fast responses to prompts from very complex models. I also hired a virtual Mac Mini from Scaleway to fix some MacOS specific bugs and seeing how quickly the inference server ran on an M2 chip was great fun too. I also enjoyed working with the guys who wanted to run the conference demo to add more improvements to the tool.
Why are you downing tools?
There have been a number of recent independent developments that provide a feature-rich and stable way to run state-of-the-art models locally and have VSCode communicate them, effectively deprecating Turbopilot. I just don't have the time to commit to competing with these alternatives and now that I've got a decent understanding of how GGML + quantization work, I'd like to spend my extra-curricular time on some other challenges.
The main reason for downing tools is that llama.cpp has feature parity with turbopilot. In fact, it's overtaken turbopilot at a rate of knots. It's not surprising, the project is amazing and has garnered a lot of interest and the community are making loads of contributions to make it better all the time. The new GGUF model format allows you to store metadata alongside the model itself so now you can run the llama server and automatically load Starcoder format models (including santacoder and wizardcoder), GPT-NEOX format models (i.e. StableCode) and LlamaCode models. Llama also provide a proxy script that converts their server API to be compatible with OpenAI which means that you can use llama's server directly with vscode-fauxcode without the need for turbopilot.
Secondly, there is a new open source VSCode plugin called Continue which provides both code autocomplete and that conversational style chat experience that CoPilot now supports. Continue can communicate directly with Llama.cpp's vanilla server without the need for the conversion proxy script. This is now my preferred way to code.
What setup do you recommend?
My recommendation is the vanilla llama.cpp server with CodeLlama 7B and Continue.
Firstly, download and build llama.cpp, I have an Nvidia 4070 so I build it with CUDA:
git clone https://github.com/ggerganov/llama.cpp.git cd llama.cpp mkdir build cd build cmake .. -DLLAMA_CUBLAS=ON -DCMAKE_CUDA_COMPILER=/usr/local/cuda/bin/nvcc make -j6
Next I download the gguf model from thebloke's repo and I run the server, offloading the whole model to GPU:
wget https://huggingface.co/TheBloke/CodeLlama-7B-Instruct-GGUF/resolve/main/codellama-7b-instruct.Q5_K_S.gguf ./bin/server -m ./codellama-7b-instruct.Q5_K_S.gguf -ngl 35
With that in place, I installed the Continue plugin in VSCode and open the sidebar. Select the '+' button to add an LLM config.
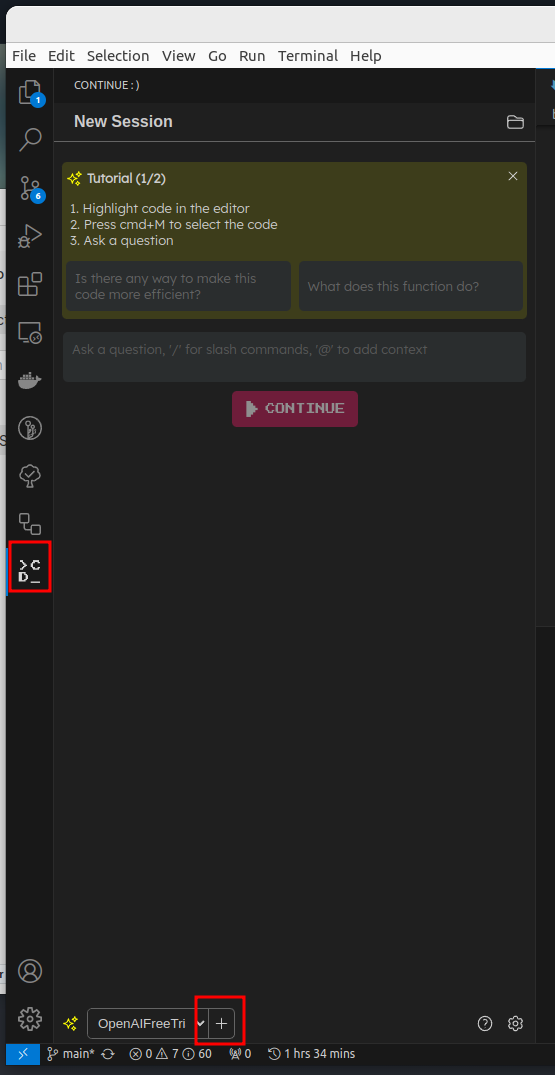
Then select llama.cpp and "Configure Model in config.py".
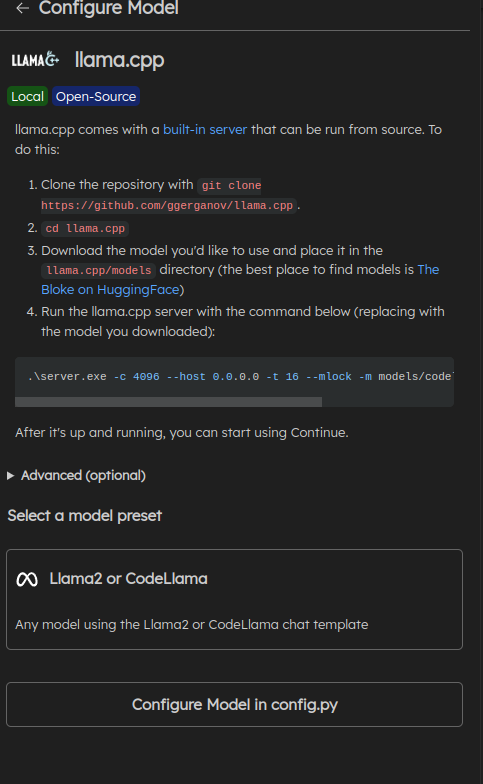
This will open up a python config.py file, append the server url to the default model and click save:
default=LlamaCpp(
model="llama2",
server_url="http://localhost:8080"
),
And now you're ready to do some coding with the new tool!
Conclusion
I've had fun building Turbopilot. It's been a great learning opportunity and helped me to expand my network and meet some cool people. However, given how much the landscape has changed since I started the project and my lack of time to devote to this project, it's right to move on and pass the torch to others in the community.
Replies & Web Activities
If you would like to comment or reply then toot me or bluesky me about this url, or send me a webmention