Knowing when to fine-tune LLMs and when to use an off-the-shelf model is a tricky question. New research can help shed a light on when each approach makes more sense and eke more performance out of off-the-shelf models without fine-tuning them.
When Fine-Tuning Beats GPT-4
Modern LLMs show impressive performance at a range of tasks out of the box. Even small models like the recent Llama 3: 8B show excellent performance at unseen tasks. However, a recent preprint from the research team at Predibase shows that small models can match and even out-perform GPT-4 when they are fine-tuned for specific tasks. Figure 5 from the paper shows a list of the tasks that were evaluated and the relative performance difference vs GPT-4.
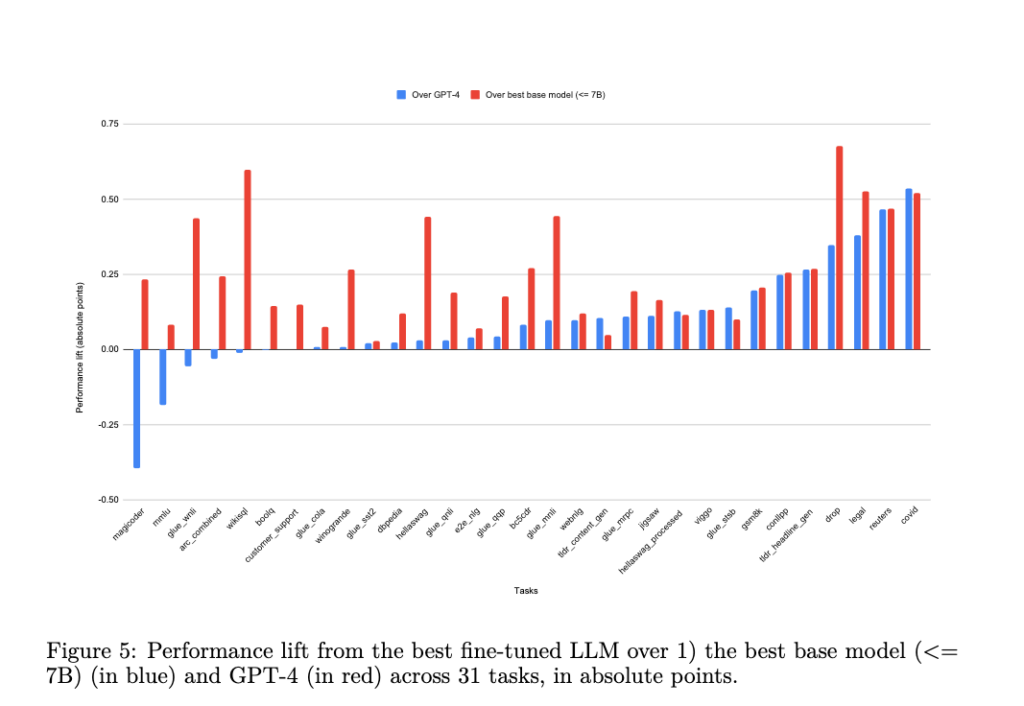
The authors note that fine-tuned models consistently outperform GPT-4 at specific, narrowly-scoped tasks like classification and information extraction. GPT-4 came out winning where tasks are more complex and open ended like generating code and multi-lingual language understanding.
Fine tuning these small models is cheaper and easier than ever before. Llama 3 can be fine-tuned on consumer GPUs and once tuned, they can be run on modest systems with ease. All of this comes with one relatively large. caveat. You need techies with at least a veneer of machine learning and MLOps expertise to do it. If you have a team with DevOps/MLOps capability you may find that this option works really well for you.
Interestingly the paper came out just after Llama 3 and Phi 3. Therefore these models are not included in the evaluation but may offer even better fine-tuned performance than their prevous-generation counterparts.
Is ICL a Good Alternative to Fine-tuning?
Another preprint published 1 day later by researchers at CMU shows that you can get performance competitive with fine-tuned models with in-context-learning (ICL). That is to say, providing a lot of example input and output pairs in your prompt can give the same sort of performance boost as fine-tuning a model. If that's the case then why bother fine-tuning? Well including huge amounts of context with every inference is going to significantly drive up API costs. It's also going to mean that each model call takes much longer. As the authors of the paper say:
...Finetuning has higher upfront cost but allows for reduced inference-time cost... finetuning on 4096 examples may still be preferable to prompting with 1000 if efficiency of inference is a major priority...
Bertsch et al, 2024
This may be an acceptable tradeoff if you are operating offline (e.g. your user is not actively waiting for a response). For example, using models to classify, summarise or extract information. However, this could be a bit of a UX vibe-killer in chat applications.
DSPy: A Wildcard
Another alternative related to in-context-learning is meta-learning. Meta-learning uses frameworks like DSPy to automatically find the best prompt for your task. It does this by systematically searching your dataset for example inputs and outputs and measuring performance. This may help you to find a compromise between context length and model performance automatically. DSPy will attempt to find the most educational training samples from your dataset whilst keeping your context short. DSPy is a little involved to get started. However, once you've got it plugged into your framework you can automatically have DSPy optimise your prompts for different models. This makes switching between API providers a doddle.
Conclusion
Both fine-tuning and providing a large number of examples in the prompt are reasonable ways to significantly boost the out-of-the-box performance of models at specific tasks. If you have a data science team in-house, a very large training dataset or require very fast inference, fine-tuning may be the way to go. Alternatively if you want to boost your model's performance without much up-front investment, it may be worth playing with in-context-learning or meta-prompting to try to improve things. However, expect slower inference speeds and higher API bills if you adopt this approach at scale.
Of course all of these approaches require you to have a well defined task, a way to measure performance at said task and some example inputs and outputs. If you're just starting out and you haven't yet built much of a dataset then zero or few-shot learning (where you describe the task in the prompt and optionally provide a handful of input/output examples) is the way to go.
Replies & Web Activities
If you would like to comment or reply then toot me or bluesky me about this url, or send me a webmention