In this post I will discuss my migration journey from Airbyte to Sling. Sling is a new lightweight data sync product that is small enough that it can run in a CI pipeline.
What's the Problem?
I'm trying to orchestrate the secure export of large amounts of data from a customer's database into cold storage. Customers can loadthis data into their favourite OLAP database and do analytics and machine learning there.
What Happened With Airbyte?
Last year I wrote about some experiments I had done with airbyte for copying data around in bulk. I was quite pleased with Airbyte at the time and it has proven to be quite robust.
Recently, Airbyte have made a few changes to the product that have made it less suitable for my work environment.
Notably:
- They deprecated their octavia CLI which I was using for programmatic sync config management. Our product's db schema is huge so manually clicking around in the UI can be very error prone.
- They recently deprecated docker and docker-compose deployment which was our favoured way of running the product. We didn't want to migrate to running kubernetes clusters for each deployment of Airbyte.
There were a couple of other sticking points that led me to want to move away from Airbyte:
- When you update the sync config it will default to running a reset and sync there and then. This is inconvenient because it puts significant load on the DB and can disrupt our clients' usage of our platform. We normally run syncs out of hours.
- Airbyte is very expensive to run per-client. It really needs a dedicated multi-core machine with 16GiB RAM (I tried 8 GiB and got thrashing and out-of-memory errors). If we had a single instance of it running for all clients it might work out cheaper. However, we are committed to infrastructure-level isolation of client data. We don't want to end up in a situationwe accidentally sync Client A's MySQL db to Client B's OLAP environment. The very thought makes me pretty shiver with anxiety.
For all of these reasons I decided to start looking at alternatives.
Exploring Alternative Solutions
I played briefly with meltano and singer but I found that they were quite sluggish for my use case. I'm not really sure why this was the case. I was finding that meltano could handle something like 10k records/second locally but 1-2k records/sec in CI. If anyone knows why that might have been, please let me know!
Eventually I stumbled across sling. Sling is written in golang and so far I've found it to be very responsive. It runs handily in a small amount of memory and supports yaml files that can be programmatically managed.
I was really excited by the resource footprint of sling vs airbyte. It's small enough that it can run in a few hundred MB of RAM rather than needing GBs. This means that it can run in our CI pipeline. In fact, the official documentation provides examples for running it inside Github Actions.
Working with Sling and Gitlab
We use Gitlab for version control and CI so I spent some time building a POC where we ship a sling replication.yaml configuration file to a repository, set some environment variables and use Gitlab Pipeline Schedules to automatically run the sync on a periodic basis.
The CI File
stages:
- run
execute:
image: slingdata/sling
stage: run
rules:
- if: '$CI_PIPELINE_SOURCE == "schedule"'
- when: manual
script:
- sling conns set GOOGLE_STORAGE type=gs bucket=${GOOGLE_STORAGE_BUCKET} key_file=${GOOGLE_SECRET_JSON}
- sling conns set MYSQL url="mysql://${MYSQL_USER}:${MYSQL_PASSWORD}@${MYSQL_HOST}:3306/${MYSQL_DBNAME}"
- sling run -r replication.yaml -d
after_script:
- |
if [ "$CI_JOB_STATUS" == "success" ]; then
curl -H "Content-type: application/json" \
--data "{\"text\": \"CI sync for \`${CI_COMMIT_REF_NAME}\` successful! :partyparrot: <${CI_PIPELINE_URL}|Click here> for details!\"}" \
-X POST $SLACK_WEBHOOK_URL
else
curl -H "Content-type: application/json" \
--data "{\"text\": \"CI sync for \`${CI_COMMIT_REF_NAME}\` failed :frowning: <${CI_PIPELINE_URL}|Click here> for details!\"}" \
-X POST $SLACK_WEBHOOK_URL
fi
Let's unpack what's happening here. I'm using the official sling docker as the main base image for my CI job. Effectively its like I've installed sling on a linux machine. I've added a rule to make sure that this run only fires when it's part of a schedule. We don't want it running every time someone pushes a change to the replication config for example.
The script simply adds connection configurations for GOOGLE_STORAGE where I'll be sending my data and MYSQL where I'll be reading it from. Then we execute the sync step with sling run.
Afterwards we send slack notifications to my org's workspace depending on whether the job succeeded or not.
The Replication Yaml
Next we also define a replication yaml. This file tells sling which connection is which (i.e. MySQL is our source and GCS is our target) and also which tables and columns to copy. This is particularly powerful since there may be specific columns that you don't want to sync (e.g user password hashes or api keys).
source: MYSQL
target: GOOGLE_STORAGE
defaults:
object: "{stream_schema}.{stream_table}"
mode: full-refresh
target_options:
format: jsonlines # this could also be CSV
compression: gzip
streams:
news_articles:
mode: full-refresh
select:
- id
- url
- is_active
- title
- summary
- created_at
The yaml file above provides default configuration for each stream - telling sling to generate gzipped newline-delineated json files in google storage.
Under the streams section we list the tables we're interested in and also use the select subsection to list columns we want (you can actually flip to an denylist approach by listing columns you don't want to select with a - in front of them which looks a bit weird because you need a dash for the yaml format and a dash for the value. It can make it clearer if you wrap them in quotes:
select: # select /everything/ except the following: - "-password" - "-my_secret_column"
We can also use a custom sql query to limit what we send over. Imagine you have a table with millions of news articles but your customer only cares about the ones categorised as "tech":
streams:
news_articles:
mode: full-refresh
sql: "SELECT * FROM news_articles WHERE category='tech'"
Configuring the Schedule
In the Gitlab Navigation tab under "Build" there should be a Pipeline Schedules button. Clicking that and then "New Schedule" should bring up a screen like this:
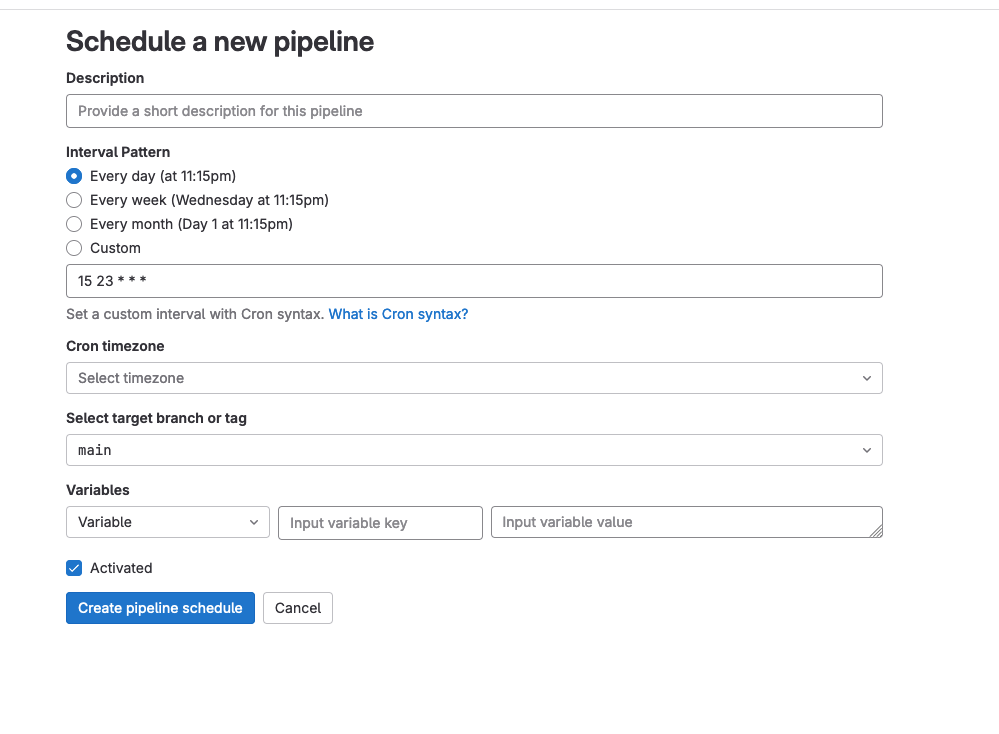
Here we can set our CI job to run on a recurring basis (if you're not comfortable using cron expressions, I recommend https://crontab.guru to help).
We need to provide values for each of the environment variables in our gitlab ci file above.
A tip for Google JSON key files: use the left-most dropdown to set a "File" variable - this takes the variable input value from the form, writes it to a file and sets the variable name to the path of the file. We can simply open up a json key file locally and copy and paste it's contents into the variable in this form.
Finally, once all the environment variables are set, we can save the schedule
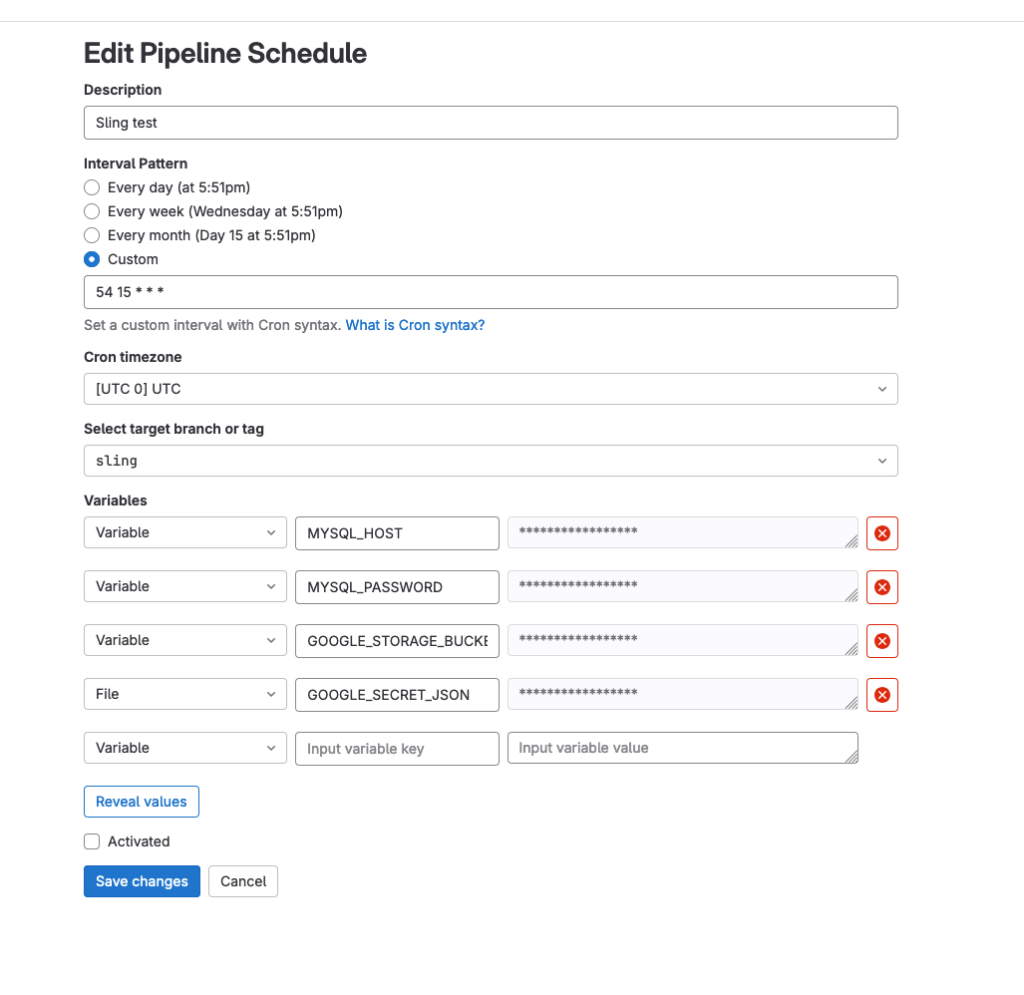
Managing Pipelines
Once you have saved your sync config you'll be able to see it in the pipelines view
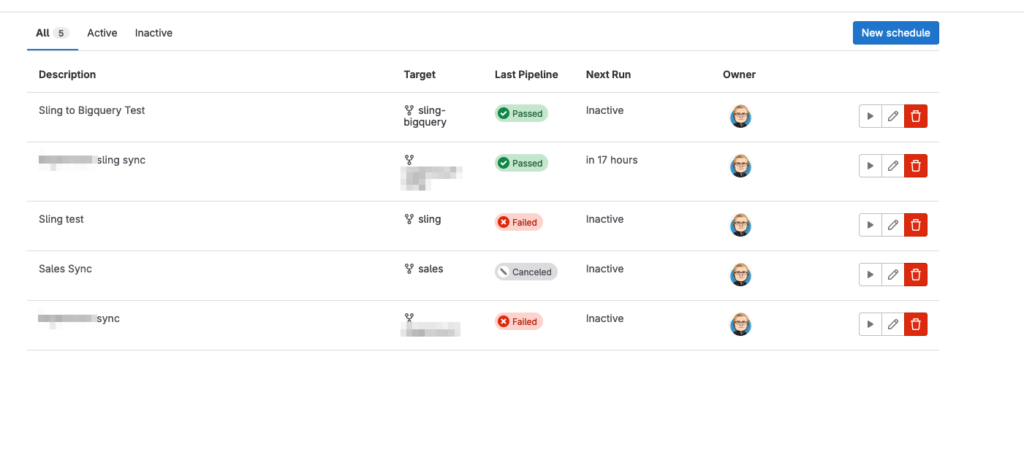
You should be able to see when the job is next scheduled to run and you can click the play button to force it to run right away. Job logs show up in your CI pipelines tab as normal.
Tips for Managing Multiple Sync Targets
Now that we've found this pattern it's made life much easier (and cheaper). I've written a python tool for automatically enabling and disabling groups of tables from our platform's schema en-masse so that we avoid manual issues.
For segregating client workloads you could have one repository per client or you could have one branch per client in the same project. The environment variable values are unique per schedule which means that it would be difficult to cross contaminate environments (unless you paste in different client's credentials during setup which would also be possible in any other situation if you are a bit gung-ho with your clipboard management).
We have branch protection rules on production/** and require a merge request and approval from an admin so that existing production sync configurations don't get accidentally overwritten.
Conclusion
Sling is a really powerful yet very lightweight tool for doing database data sync. It's been really great to be able to vastly simplify our company's data sync offering and stop having to set up expensive servers for every customer that needs this functionality. Hopefully this post is useful to others looking to try out sling. If you're interested in the tool check out their documentation, github page. The maintainer Fritz is very responsive and active when it comes to issues and the project discord chat so those are also great resources if you have any questions.
Replies & Web Activities
If you would like to comment or reply then toot me or bluesky me about this url, or send me a webmention