The relatively recently released Phi 3.5 model series includes a mixture-of-experts model featuring 16 x 3.3 Billion parameter expert models. It activates these experts two at a time resulting in pretty good performance but only 6.6 billion parameters held in memory at once. I recently wanted to try running Phi MoE 3.5 on my macbook but was blocked from doing so using my usual method whilst support is built into llama.cpp and then ollama.
I decided to try out another library, mistral.rs, which is written in the rust programming language and already supports these newer models. It required a little bit of fiddling around but I did manage to get it working and the model is relatively responsive.
Getting Our Dependencies and Building Mistral.RS
To get started you will need to have the rust compiler toolchain installed on your macbook including rustc and cargo. The easiest way to do this is via brew:
brew install rust
You'll also need to grab the code for the project
git clone https://github.com/EricLBuehler/mistral.rs.git
Once you have both of these in place we can build the project. Since we're running on Mac, we want the compiler to make use of apple Metal which allows the model to use the GPU capabilities of the M-series chip to accelerate the model.
cd mistral.rs cargo install --path mistralrs-server --features metal
This command may take a couple of minutes to run. The compiled server will be saved in the target/release folder relative to your project folder.
Running the Model with Quantization
The default instructions in the project readme work but you might find it takes up a lot of memory and takes a really long time to run. That's because, by default mistral.rs does not do any quantization so running the model requires 12GB of memory.
mistral.rs supports in-situ-quantisation which essentially means that the framework loads the model up and does the quantisation at run time (as opposed to requiring you to download a GGUF file that was already quantized). I recommend running the following:
./target/release/mistralrs-server --isq Q4_0 -i plain -m microsoft/Phi-3.5-mini-instruct -a phi3
In this mode we use ISQ to quantize the model down to 4bit mode (--isq Q4_0). You should be able to chat to the model through the terminal
Running as a Server
Mistral.rs provides a HTTP API that is compatible with OpenAI standards. To run in server mode we remove the -i argument and replace it with a port number to run on --port 1234:
./target/release/mistralrs-server --port 1234 --isq Q4_0 plain -m microsoft/Phi-3.5-mini-instruct -a phi3
You can then use an app like Postman or Bruno to interact with your model:
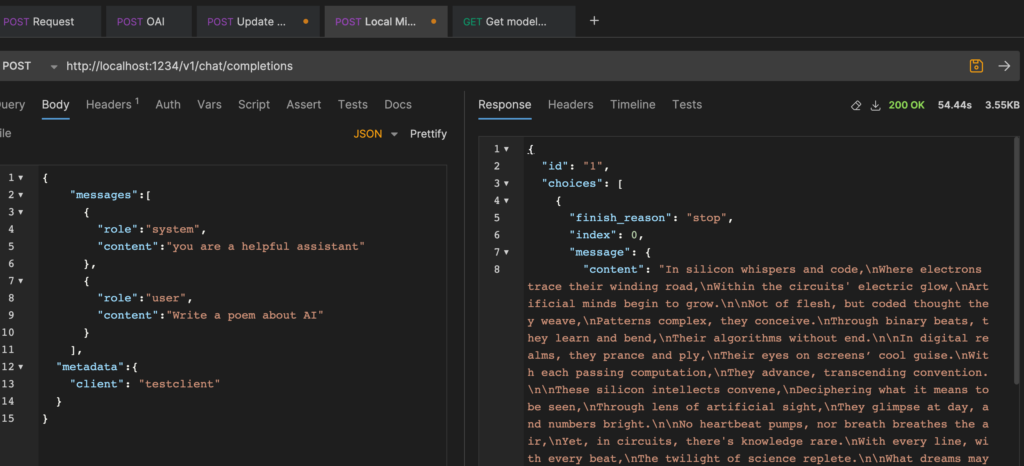 Running the Vision Model
Running the Vision Model
To run the vision model, we just need to make a couple of changes to our command line arguments:
./target/release/mistralrs-server --port 1234 --isq Q4_0 vision-plain -m microsoft/Phi-3.5-vision-instruct -a phi3v
We still want to use ISQ but this time we swap plain for vision-plain, we swap the model name for the vision equivalent and we change the architecture -a phi3 to -a phi3v.
Likewise we can now interact with the model via HTTP tooling. Here's a response based on the example from the documentation:
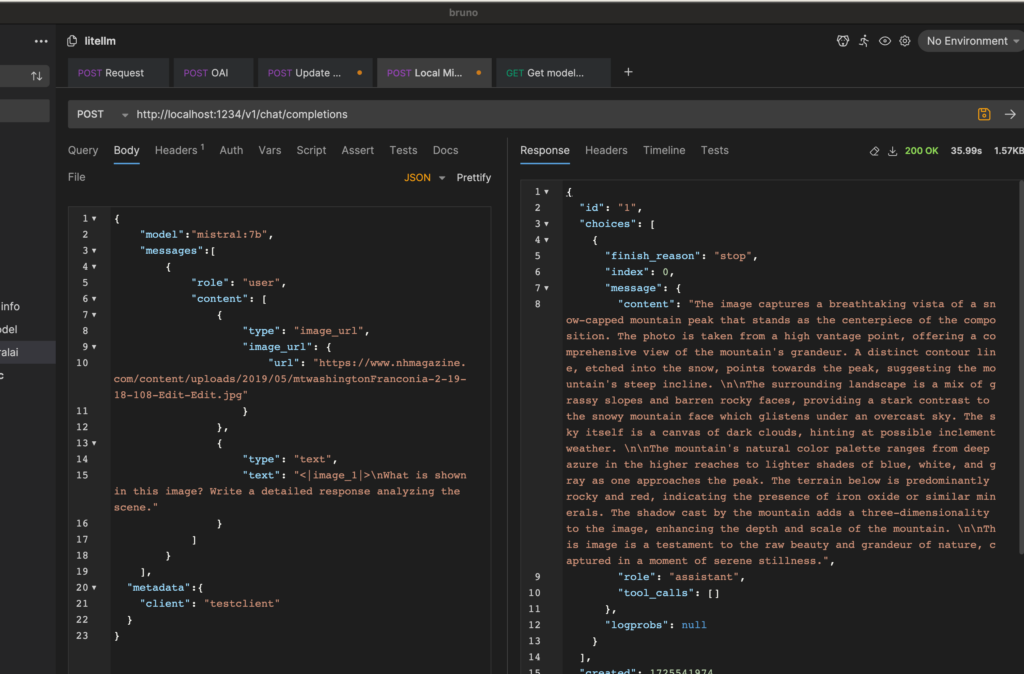 Running on Linux and Nvidia
Running on Linux and Nvidia
I am still struggling to get mistral.rs to build on Linux at the moment, the docker images that are provided by the project don't seem to play ball with my systems. Once I figure this out I'll release an updated version of this blog.
Replies & Web Activities
If you would like to comment or reply then toot me or bluesky me about this url, or send me a webmention
1 Likes
2 Reposts